
原華為“天才少年”4萬(wàn)字演講風(fēng)靡國(guó)內(nèi)人工智能學(xué)術(shù)圈
近期,一篇4萬(wàn)字的演講風(fēng)靡于國(guó)內(nèi)人工智能(AI)學(xué)術(shù)圈。
原華為"天才少年"、Logenic AI公司聯(lián)合創(chuàng)始人李博杰博士,日前發(fā)表了一篇關(guān)于AI Agent思考的文章,題為"AI Agent 應(yīng)該更有趣還是更有用"。
李博杰在這篇文章中表示,AI的發(fā)展目前有兩個(gè)方向,一個(gè)是有趣的AI,也就是更像人的AI;另外一個(gè)方向就是更有用的AI,也就是更像工具的AI。但目前的AI技術(shù),要么是只有趣但沒(méi)用,要么是只有用但是不像人,"不好玩"。
李博杰指出,通用人工智能(AGI)的目標(biāo)是,兼具慢思考和類人屬性的 AI Agent,然而當(dāng)前 AI Agent 和人類夢(mèng)想之間存在巨大的差距。
李博杰坦言,Video Diffusion 是一個(gè)更為終極的技術(shù)路線。盡管大模型的成本一定會(huì)快速降低,但他不建議貿(mào)然自己去做基礎(chǔ)模型。
"如果沒(méi)有拳打OpenAI、腳踢Anthropic的實(shí)力,在效果上比不過(guò)最好的閉源模型,成本上也比不上開源模型。"李博杰表示。
據(jù)悉,李博杰今年31歲 (1992年生),曾任華為2012實(shí)驗(yàn)室中央軟件研究所計(jì)算機(jī)網(wǎng)絡(luò)與協(xié)議實(shí)驗(yàn)室、分布式與并行軟件實(shí)驗(yàn)室助理科學(xué)家、副首席專家,并且以第一批"天才少年"的身份于2019年加入華為,職級(jí)P20 (技術(shù)專家A級(jí)別)。
早在2010年,他進(jìn)入中國(guó)科學(xué)技術(shù)大學(xué)少年班學(xué)院學(xué)習(xí)。在校期間,擔(dān)任中科大鏡像站USTC Mirrors的維護(hù)者。2014年,李博杰以聯(lián)合培養(yǎng)博士生的身份,加入中國(guó)科學(xué)技術(shù)大學(xué)與微軟亞洲研究院(MSRA)的聯(lián)合項(xiàng)目。
幾乎同時(shí),2019年,李博杰獲得中國(guó)科學(xué)技術(shù)大學(xué)與微軟亞洲研究院的合作培養(yǎng)博士生項(xiàng)目中取得計(jì)算機(jī)科學(xué)學(xué)位,導(dǎo)師為張霖濤教授和陳恩紅教授。
2023年7月,李博杰離開華為后成立了Logenic AI,致力于成為人類的數(shù)字化延伸。憑借尖端的AIGC基礎(chǔ)設(shè)施,Logenic AI 能夠協(xié)作制作和服務(wù)多模式角色Agent,"元宇宙"、以及數(shù)字雙胞胎等角色。
李博杰表示,"我們都相信 AGI 肯定會(huì)到來(lái),唯一值得爭(zhēng)論的是到達(dá) AGI 的增長(zhǎng)曲線是怎樣的,是這一波自回歸模型隨著 scaling law,直接高速增長(zhǎng)到 AGI;還是這一波自回歸模型也會(huì)遇到瓶頸,AGI 還需要等待下一波技術(shù)革命。10 年前 ResNet 掀起 CV 革命的時(shí)候,很多人都對(duì) AI 的發(fā)展預(yù)期過(guò)于樂(lè)觀。這一波 Transformer 會(huì)是通向 AGI 的坦途嗎?"
李博杰強(qiáng)調(diào),AI Agent 的創(chuàng)作者可以盈利。因此,好看的皮囊、有趣的靈魂、有用的 AI、低成本和去中心化,AI Agent 將推動(dòng)整個(gè) AI 領(lǐng)域持續(xù)創(chuàng)新和健康發(fā)展。
"我們相信,在人類世界的數(shù)字延伸中,有趣的靈魂終會(huì)相遇。"李博杰稱。
以下是李博杰演講內(nèi)容全文,共約4萬(wàn)字,Enjoy:

非常榮幸來(lái)到科大校友會(huì) AI 沙龍分享一些我對(duì) AI Agent 的思考。
我是 1000(2010 級(jí)理科實(shí)驗(yàn)班)的李博杰,2014-2019 年在中科大和微軟亞洲研究院讀聯(lián)合培養(yǎng)博士,2019-2023 年是華為首屆天才少年,如今我跟一批科大校友一起在做 AI Agent 領(lǐng)域的創(chuàng)業(yè)。
今天(去年12月)是湯曉鷗教授的頭七,因此我特別把今天的PPT調(diào)成了黑色背景,這也是我第一次用黑色背景的PPT做報(bào)告。我也希望,隨著AI技術(shù)的發(fā)展,未來(lái)每個(gè)人都可以有自己的數(shù)字分身,實(shí)現(xiàn)靈魂在數(shù)字世界中的永生,在這個(gè)世界里生命不再有限,也就不再有分離的悲傷。
AI:有趣和有用
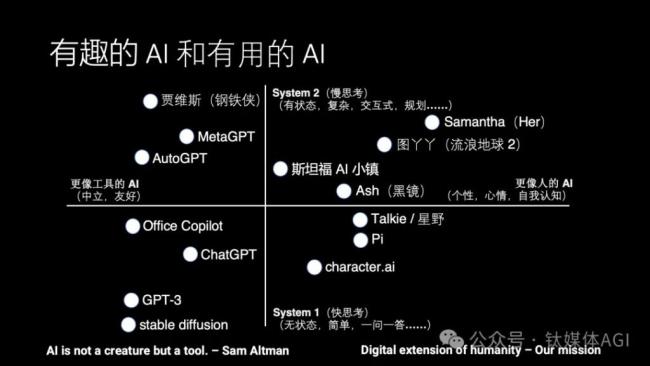
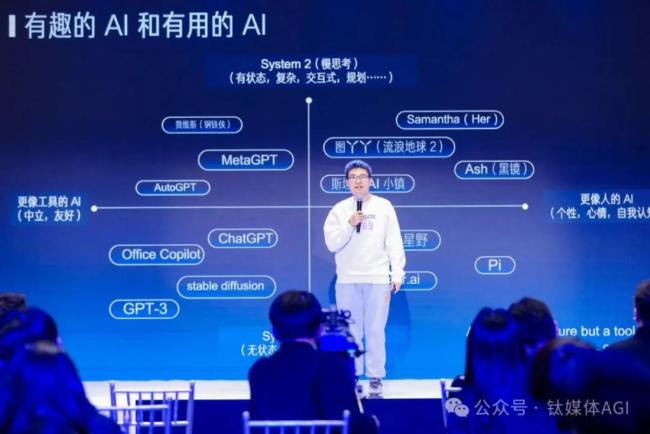
AI的發(fā)展目前一直有兩個(gè)方向,一個(gè)是有趣的AI,也就是更像人的AI;另外一個(gè)方向就是更有用的AI,也就是更像工具的AI。
AI 應(yīng)該更像人還是更像工具呢?其實(shí)是有很多爭(zhēng)議的。比如說(shuō) OpenAI 的 CEO Sam Altman 就說(shuō),AI 應(yīng)該是一個(gè)工具,它不應(yīng)該是一個(gè)生命。而很多科幻電影里的 AI 其實(shí)更像人,比如說(shuō) Her 里面的 Samantha,還有《流浪地球 2》里面的圖丫丫,黑鏡里面的 Ash,所以我們希望能把這些科幻中的場(chǎng)景帶到現(xiàn)實(shí)。只有少數(shù)科幻電影里面的 AI 是工具向的,比如《鋼鐵俠》里面的賈維斯。
除了有趣和有用這個(gè)水平方向的之外,還有另外一個(gè)上下的維度,就是快思考和慢思考。這是一個(gè)神經(jīng)科學(xué)的概念,出自一本書《思考,快與慢》,它里面就說(shuō)人的思考可以分為快思考和慢思考。
所謂的快思考就是不需要過(guò)腦子的基礎(chǔ)視覺、聽覺等感知能力和說(shuō)話等表達(dá)能力,像 ChatGPT、stable diffusion 這種一問(wèn)一答、解決特定問(wèn)題的 AI 可以認(rèn)為是一種工具向的快思考,你不問(wèn)它問(wèn)題的時(shí)候,它不會(huì)主動(dòng)去找你。而 Character AI、Inflection Pi 和 Talkie(星野)這些 AI Agent 產(chǎn)品都是模擬一個(gè)人或者動(dòng)漫游戲角色的對(duì)話,但這些對(duì)話不涉及復(fù)雜任務(wù)的解決,也沒(méi)有長(zhǎng)期記憶,因此只能用來(lái)閑聊,沒(méi)法像 Her 里面的 Samantha 那樣幫忙解決生活和工作中的問(wèn)題。
而慢思考就是有狀態(tài)的復(fù)雜思考,也就是說(shuō)如何去規(guī)劃和解決一個(gè)復(fù)雜的問(wèn)題,先做什么、后做什么。比如 MetaGPT 寫代碼是模擬一個(gè)軟件開發(fā)團(tuán)隊(duì)的分工合作,AutoGPT 是把一個(gè)復(fù)雜任務(wù)拆分成很多個(gè)階段來(lái)一步步完成,雖然這些系統(tǒng)在實(shí)用中還有很多問(wèn)題,但已經(jīng)是一個(gè)具備慢思考能力的雛形了。
遺憾的是,現(xiàn)有產(chǎn)品中幾乎沒(méi)有在第一象限,兼具慢思考和類人屬性的 AI Agent。斯坦福 AI 小鎮(zhèn)是個(gè)不錯(cuò)的學(xué)術(shù)界嘗試,但斯坦福 AI 小鎮(zhèn)里面沒(méi)有真人的交互,而且 AI Agent 一天的作息時(shí)間表都是事先排好的,因此并不是很有趣。
有趣的是,科幻電影里面的AI其實(shí)大部分是在這個(gè)第一象限。因此這就是目前 AI Agent 和人類夢(mèng)想之間的差距。
因此我們?cè)谧龅氖虑楦?Sam Altman 說(shuō)的正好相反,我們希望讓 AI 更像人,同時(shí)又具備慢思考的能力,最終演進(jìn)成一個(gè)數(shù)字生命。

請(qǐng)輸入圖說(shuō)
今天大家都在講AGI的故事,AGI就是通用人工智能。什么是AGI呢?我覺得它又需要有趣,又需要有用。
有趣的方面,就是它需要能夠有自主思考的能力、有自己的個(gè)性和感情。而有用的方面,就是AI能夠解決工作、生活中的問(wèn)題。現(xiàn)在的AI要么是只有趣但沒(méi)用,要么是只有用但是不像人,不好玩。
比如說(shuō)像 Character AI 之類的角色扮演產(chǎn)品,它不能幫你完成工作或者生活中的問(wèn)題,但是它可以模擬一個(gè) Elon Musk、Donald Trump 或者原神里面的派蒙。我看過(guò)一個(gè)分析報(bào)告,說(shuō) Character AI 有上千萬(wàn)的用戶,但每個(gè)月的營(yíng)收只有幾十萬(wàn)美金,相當(dāng)于只有幾萬(wàn)付費(fèi)用戶。大多數(shù)用戶跟每個(gè)虛擬角色都是聊 10 分鐘、20 分鐘就不知道該說(shuō)什么了。那為什么它的用戶留存不高、付費(fèi)率也低呢?因?yàn)樗葲](méi)有給人提供情緒價(jià)值,又沒(méi)有給人提供實(shí)用價(jià)值。
而另一方面就是有用的AI,比如各種Copilot,他們又都是冷冰冰的,問(wèn)一句答一句,完全是一個(gè)工具。這些工具甚至記不住你之前干過(guò)什么,記不住你的喜好和習(xí)慣。那么用戶自然只會(huì)在需要這個(gè)工具的時(shí)候想起來(lái)用它,不需要的時(shí)候就會(huì)丟到一邊。
我認(rèn)為未來(lái)真正有價(jià)值的AI就像電影《Her》里面的Samantha,她首先是一個(gè)操作系統(tǒng)的定位,能夠幫主人公去解決很多生活中、工作中的問(wèn)題,幫他整理郵件等等,而且比傳統(tǒng)的操作系統(tǒng)做得又快又好。同時(shí)它又有記憶、有感情、有意識(shí),它不像一個(gè)電腦,而是像一個(gè)人。因此在感情空窗期的主人公 Theodore 就逐漸愛上了他的操作系統(tǒng) Samantha。當(dāng)然并不是所有人都把 Samantha 作為虛擬伴侶,劇中也說(shuō)了,只有 10% 的用戶跟他們的操作系統(tǒng)發(fā)展了浪漫關(guān)系。這樣的 AI Agent 我認(rèn)為才是真正有價(jià)值的。
另外值得說(shuō)道的一點(diǎn)是,全劇中這個(gè)Samantha只有語(yǔ)音交互,沒(méi)有視覺形象,更不是機(jī)器人。目前AI的能力也恰好是語(yǔ)音和文字很成熟,但視頻生成就不夠成熟,人形機(jī)器人也不夠成熟。《黑鏡》里面的機(jī)器人Ash就是個(gè)反例。這部劇里面先是用女主過(guò)世男友Ash的社交網(wǎng)絡(luò)資料制作了一個(gè)語(yǔ)音伴侶,直接把女主給弄哭了,其實(shí)做出那個(gè)語(yǔ)音伴侶現(xiàn)在的技術(shù)已經(jīng)綽綽有余了。后來(lái)女主加錢升級(jí),上傳了一堆視頻資料,買了一個(gè)長(zhǎng)得像Ash的人形機(jī)器人,其實(shí)現(xiàn)在的技術(shù)也做不到,但就算如此,Ash的女友還是覺得不像,因此把他鎖在閣樓里面了。這里面就有個(gè)恐怖谷效應(yīng),如果做得不夠逼真,就保持一定的距離。
順便說(shuō)一句,《黑鏡》里面女主先是文字聊天,然后說(shuō)了一句 Can you talk to me?然后就接通電話了。試用我們 AI Agent 的一個(gè)朋友還真的也這么問(wèn)我們的 AI Agent,結(jié)果我們的 AI Agent 回答,我是一個(gè) AI,只能文字交流,不會(huì)說(shuō)話。他還截圖發(fā)給我,問(wèn)我說(shuō)好的語(yǔ)音電話呢,我說(shuō)打語(yǔ)音電話需要按那個(gè)打電話的按鈕啊。所以這些經(jīng)典的 AI 劇真的要一個(gè)鏡頭一個(gè)鏡頭的拆解分析,里面有很多產(chǎn)品設(shè)計(jì)的細(xì)節(jié)。

巧合的是,我們的第一臺(tái) H100 訓(xùn)練服務(wù)器就是在洛杉磯最老的郵局,后來(lái)改造成了一個(gè)金庫(kù),又改造成了一個(gè)數(shù)據(jù)中心。這個(gè)地方在洛杉磯的市中心,距離《Her》的拍攝地 Bradbury Building 只有不到 1 英里。
這個(gè)數(shù)據(jù)中心也是洛杉磯的互聯(lián)網(wǎng)交換局(Internet Exchange),距離 Google 和 Cloudflare 入口服務(wù)器的延遲都在 1 毫秒以內(nèi),其實(shí)都在這棟樓里面。從百年前的郵局到今天的互聯(lián)網(wǎng)交換局,真的是挺有意思的。
有趣的AI
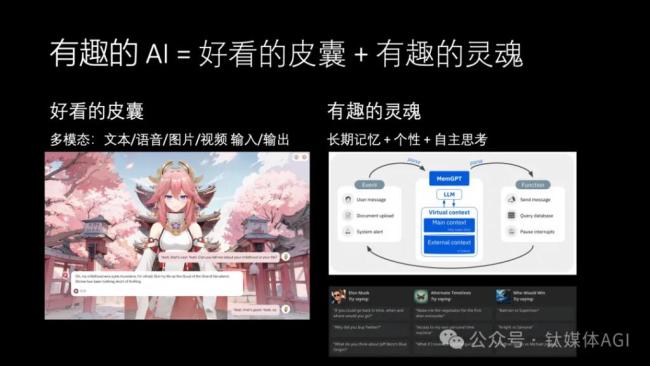
那么我們首先來(lái)看一看如何去構(gòu)建一個(gè)真正有趣的AI。有趣的AI我認(rèn)為就像一個(gè)有趣的人,可以分為好看的皮囊和有趣的靈魂這兩個(gè)方面。
好看的皮囊就是它能夠聽得懂語(yǔ)音,看得懂文本、圖片和視頻,有這樣一個(gè)視頻、語(yǔ)音的形象,能夠跟人實(shí)時(shí)交互。
有趣的靈魂就是它需要像人一樣能夠去獨(dú)立思考,有長(zhǎng)期記憶,有自己的個(gè)性。
下面我們就分別從好看的皮囊和有趣的靈魂兩個(gè)方面來(lái)講。
好看的皮囊:多模態(tài)理解能力

說(shuō)到好看的皮囊,很多人認(rèn)為只要有一個(gè)3D的形象能夠在這兒搖頭晃腦地展示就行了。但是我認(rèn)為更關(guān)鍵的一部分是AI能夠去看到,并且理解周圍的世界,就是他的視覺理解能力是很關(guān)鍵的,不管是機(jī)器人還是可穿戴設(shè)備,還是手機(jī)上的攝像頭。
比如說(shuō)像Google的Gemini演示視頻就做得不錯(cuò),雖然它做了剪輯,但是如果我們真正能做到它這么好的效果,是一定不愁用戶的。
我們回顧一下Gemini演示視頻中的幾個(gè)片段,給一個(gè)畫鴨子的視頻它能描述鴨子是什么,給一個(gè)餅干和橘子能對(duì)比它們的不同,給一個(gè)簡(jiǎn)筆畫小游戲知道該往哪邊走,給兩團(tuán)毛線可以畫出一個(gè)用它能織出的毛絨玩具,給幾個(gè)行星的圖能夠?qū)λ鼈冋_排序,給一個(gè)貓?zhí)瞎褡拥囊曨l能夠描述發(fā)生了什么。
雖然效果非常驚艷,其實(shí)仔細(xì)想想,這些場(chǎng)景都不是很難做出來(lái)的,只要會(huì)看圖說(shuō)話,也就是給圖片生成一個(gè)比較好的caption,這些問(wèn)題大模型就都能回答了。
語(yǔ)音能力也是非常關(guān)鍵的。我 10 月份基于 Google ASR/TTS 和 GPT-4 做了一個(gè)語(yǔ)音聊天 AI Agent,一聊聊了一整天,室友還以為我在跟老婆煲電話粥,就沒(méi)來(lái)打擾我。當(dāng)他知道我是在跟 AI 聊天的時(shí)候,說(shuō)我怎么能跟 AI 聊這么久。我給他看了看我們的聊天記錄,他說(shuō) AI 確實(shí)挺能聊的,他用 ChatGPT 不愿意聊這么久,是因?yàn)閼械么蜃帧?/p>

我認(rèn)為,多模態(tài)大模型有三條路。第一條是用多模態(tài)數(shù)據(jù)端到端預(yù)訓(xùn)練的模型,Google 的 Gemini 就是這么做出來(lái)的,最近 Berkeley 的 LVM 也是端到端多模態(tài)的,我認(rèn)為這是最有前景的一個(gè)方向。當(dāng)然這條路需要非常多的計(jì)算資源。
現(xiàn)在還有一種工程化的方案,是用膠水層去粘接已經(jīng)訓(xùn)練好的模型,比如目前圖片理解做得最好的 GPT-4V,還有學(xué)術(shù)界開源的 MiniGPT-4/v2,LLaVA 等等。膠水層是我的叫法,專業(yè)名詞叫做 projection layer,比如右上角這個(gè) MiniGPT 架構(gòu)圖中,標(biāo)著 "" 的 6 個(gè)框就是 projection layer。
輸入的圖片、語(yǔ)音、視頻分別通過(guò)不同的 encoder 去做編碼,編碼結(jié)果經(jīng)過(guò) projection layer 映射到 token,輸入給 Transformer 大模型。大模型的輸出 token 經(jīng)過(guò) projection layer,分別映射到圖片、語(yǔ)音、視頻的解碼器,這樣就可以生成圖片、語(yǔ)音、視頻了。
在這個(gè)膠水層粘接的方案里,可以看到 encoder、decoder 和大模型上面都標(biāo)著 "??",那就是凍結(jié)權(quán)重的意思。使用多模態(tài)數(shù)據(jù)訓(xùn)練的時(shí)候,只修改 projection layer 部分的權(quán)重,不修改其他部分的權(quán)重,這樣訓(xùn)練的成本就能大大降低,只要幾百美金就能訓(xùn)練出一個(gè)多模態(tài)大模型。
第三條路是第二條路推向極致的方案,連 projection layer 都不要了,直接用文本去粘接encoder、decoder和文本大模型,不需要做任何訓(xùn)練。例如語(yǔ)音部分就是先做語(yǔ)音識(shí)別,把語(yǔ)音轉(zhuǎn)換成文字輸入給大模型,然后再把大模型的輸出送給語(yǔ)音合成模型生成音頻。不要小看這種聽起來(lái)很土的方案,在語(yǔ)音領(lǐng)域,目前這種方案還是最靠譜的,現(xiàn)有的多模態(tài)大模型在識(shí)別和合成人類說(shuō)話語(yǔ)音方面都不太行。
Google Gemini 的語(yǔ)音對(duì)話響應(yīng)延遲只有 0.5 秒,這是一個(gè)真人都很難達(dá)到的延遲,真人的延遲一般在 1 秒左右。我們現(xiàn)有的語(yǔ)音聊天產(chǎn)品,比如 ChatGPT,語(yǔ)音對(duì)話延遲高達(dá) 5~10 秒。因此大家才會(huì)覺得 Google Gemini 的效果非常驚艷。
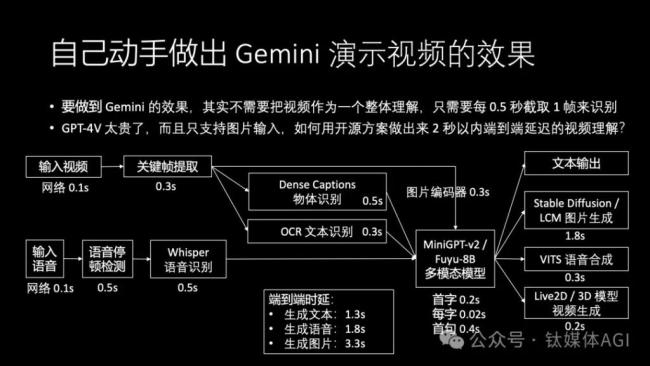
那么這個(gè)效果是不是很難做出來(lái)呢?其實(shí)我們現(xiàn)在用開源的方案就可以做出來(lái)2秒以內(nèi)的語(yǔ)音對(duì)話響應(yīng)延遲,而且還包含實(shí)時(shí)視頻理解。
我們先不考慮視覺部分,先只看語(yǔ)音部分。在一個(gè)語(yǔ)音電話里,收到語(yǔ)音后首先做停頓檢測(cè),發(fā)現(xiàn)用戶說(shuō)話結(jié)束了,就把這一段音頻送到Whisper去做語(yǔ)音識(shí)別。停頓檢測(cè)比如人聲結(jié)束后等待0.5秒,然后Whisper語(yǔ)音識(shí)別大概需要0.5秒。
然后送到文本模型去做生成,用開源模型生成的速度其實(shí)非常快,比如最近比較火的 Mixtral 8x7B MoE 模型,輸出第一個(gè) token 只需要 0.2 秒,每秒輸出 50 個(gè) token 不是問(wèn)題,那么第一句話假設(shè)有 20 個(gè) token,就需要 0.4 秒。第一句話生成完了,就交給語(yǔ)音合成模型去合成語(yǔ)音,VITS 只需要 0.3 秒。
加上0.1秒的網(wǎng)絡(luò)時(shí)延,這樣端到端算下來(lái)只要1.8秒的延遲,已經(jīng)比市面上的大多數(shù)實(shí)時(shí)語(yǔ)音電話產(chǎn)品好很多了。比如ChatGPT語(yǔ)音電話的延遲是5~10秒。而且我們的方案中,停頓檢測(cè)和語(yǔ)音識(shí)別部分的延遲還有優(yōu)化空間。
我們?cè)倏?Google Gemini 演示的視頻理解場(chǎng)景。
因?yàn)槲覀儸F(xiàn)在的多模態(tài)模型輸入的基本都是圖片,而不是流式視頻,所以首先需要把視頻變成圖片,截取關(guān)鍵幀。比如每0.5秒截取一幀,這里面就有平均0.3秒的延遲。圖片可以直接送進(jìn)MiniGPT-v2或者Fuyu-8B這樣的開源多模態(tài)模型。但是由于這些模型比較小,實(shí)際用起來(lái)效果并不是很好,跟GPT-4V差距比較大。
因此我們可以采取傳統(tǒng)CV與多模態(tài)大模型相結(jié)合的方案,用 Dense Captions 這個(gè)技術(shù)識(shí)別出圖片中的所有物體及其位置,并且用 OCR 識(shí)別圖片中的所有文本。再把 OCR 結(jié)果,Dense Captions 的物體識(shí)別結(jié)果作為原始圖片的補(bǔ)充文字,都輸入到 MiniGPT-v2 或者 Fuyu-8B 這種多模態(tài)大模型里面。對(duì)于菜單、說(shuō)明書一類的圖片,OCR 的作用是非常大的,因?yàn)閱慰慷嗄B(tài)大模型經(jīng)常識(shí)別不清楚大塊文字。
這個(gè)識(shí)別圖片中物體和文字的步驟增加了額外的 0.5 秒延遲,但是我們看一下延遲分解,就會(huì)發(fā)現(xiàn)視頻部分根本不是瓶頸,只有 0.9 秒,而語(yǔ)音輸入部分反而是瓶頸,需要 1.1 秒。在 Google Gemini 這個(gè)演示場(chǎng)景中,從看到視頻到AI文字開始輸出只要1.3秒,從看到視頻到AI語(yǔ)音開始播放只要1.8秒,雖然沒(méi)有演示視頻的 0.5 秒這么酷炫,但也足夠完爆市面上的所有產(chǎn)品了。這里面用的還全部都是開源模型,一點(diǎn)訓(xùn)練都不需要做。如果公司自己有一些自己訓(xùn)練和優(yōu)化模型的能力,想象空間就更大了。
Google Gemini 演示視頻分為兩種任務(wù):生成文本/語(yǔ)音和生成圖片。在生成圖片的時(shí)候,可以根據(jù)文本,調(diào)用 Stable Diffusion 或者最近新出的 LCM 模型,只要 4 個(gè) step 甚至 1 個(gè) step 就可以生成圖片,圖片生成的延遲可以做到 1.8 秒,那么從看到圖到生成圖的端到端時(shí)間就只有 3.3 秒,也是非常快的了。
好看的皮囊:多模態(tài)生成能力
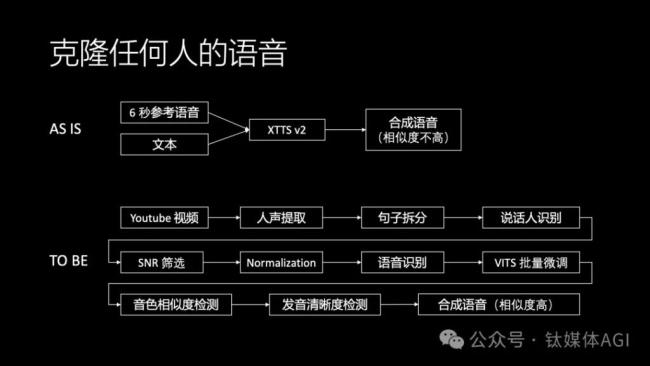
語(yǔ)音克隆是制作名人或者動(dòng)漫游戲角色的重要技術(shù),目前 ElevenLabs 做得是最好的,但是 ElevenLabs 的 API 很貴。XTTS v2 之類的開源方案合成語(yǔ)音的相似度不高。
我認(rèn)為要想語(yǔ)音克隆效果好,還是要靠大量的語(yǔ)音數(shù)據(jù)來(lái)做訓(xùn)練。但是傳統(tǒng)語(yǔ)音訓(xùn)練所需的數(shù)據(jù)一般對(duì)質(zhì)量要求很高,必須是錄音棚里面錄制的口齒清晰的語(yǔ)音數(shù)據(jù),因此采集語(yǔ)音數(shù)據(jù)的成本很高。但我們不可能要求名人到錄音棚里去給我們專門錄制語(yǔ)音,只能用YouTube等公開視頻的語(yǔ)音做訓(xùn)練。YouTube 語(yǔ)音往往是訪談形式,里面有多個(gè)人說(shuō)話,而且有背景噪聲,名人說(shuō)話的過(guò)程中也可能有結(jié)巴和口齒不清。如何用這樣的語(yǔ)音訓(xùn)練語(yǔ)音克隆呢?
我們搭建了一套基于VITS搭建的語(yǔ)音克隆流水線,可以自動(dòng)把視頻中的人聲從背景噪聲中區(qū)分出來(lái),拆分成句子之后,識(shí)別出有哪幾個(gè)說(shuō)話人,針對(duì)我們想要的人的語(yǔ)音,篩選出其中信噪比較高的語(yǔ)音,然后識(shí)別出文字,最后這些清洗過(guò)的語(yǔ)音和文字送去做批量微調(diào)。
微調(diào)過(guò)程也是很有技術(shù)含量的。首先,微調(diào)的基礎(chǔ)語(yǔ)音需要是比較相似的語(yǔ)音,比如一個(gè)男生的語(yǔ)音用一個(gè)女生的語(yǔ)音作為基礎(chǔ)去微調(diào),那效果肯定不好。如何從語(yǔ)音庫(kù)里找到相似的語(yǔ)音來(lái)做微調(diào)是需要一個(gè)音色相似度檢測(cè)模型,類似聲紋識(shí)別的模型。像ElevenLabs的基礎(chǔ)語(yǔ)音模型中就已經(jīng)包含了大量不同音色人的高質(zhì)量數(shù)據(jù),因此在語(yǔ)音克隆的時(shí)候,很多時(shí)候能夠從語(yǔ)音庫(kù)中找到很相似的語(yǔ)音,這樣不需要做微調(diào)就能zero-shot生成不錯(cuò)的語(yǔ)音。
其次,VITS訓(xùn)練過(guò)程中不能根據(jù)簡(jiǎn)單的loss判斷收斂,以往都是要靠人耳朵去聽哪個(gè)epoch的效果最好,這樣就需要大量的人工成本。我們開發(fā)了音色相似度檢測(cè)模型和發(fā)音清晰度檢測(cè)模型,可以自動(dòng)判斷語(yǔ)音的微調(diào)結(jié)果哪個(gè)更好。
(注:這個(gè)報(bào)告是2023年12月做的,目前GPT-soVITS的路線比VITS更好,可以實(shí)現(xiàn)zero-shot語(yǔ)音克隆,不再需要收集大量高質(zhì)量語(yǔ)音做訓(xùn)練。開源模型可以合成的語(yǔ)音質(zhì)量終于逼近ElevenLabs的水平了。)

很多人認(rèn)為不需要自研語(yǔ)音合成模型,直接調(diào)用 ElevenLabs、OpenAI 或者 Google Cloud 的 API 就行了。
但是 ElevenLabs 的 API 非常貴,如果走零售定價(jià),每 1K 字符需要 0.18 美金,按照一個(gè) token 4 個(gè)字符計(jì)算,相當(dāng)于 $0.72 / 1K tokens 了,這是比GPT-4Turbo都要貴24倍的。ElevenLabs 雖然效果好,但是如果 to C 產(chǎn)品大規(guī)模使用,這個(gè)價(jià)格是真的燒不起。
OpenAI 和 Google Cloud 的語(yǔ)音合成 API 不支持語(yǔ)音克隆,只有那幾個(gè)固定的聲音,這樣就沒(méi)法克隆名人語(yǔ)音了,只能做一個(gè)冷冰冰的機(jī)器人播報(bào)。但即使這樣,成本也是比 GPT-4 Turbo 貴 1 倍的,也就是成本的大頭不是花在大模型上,而是花在語(yǔ)音合成上。
大概也是因?yàn)檎Z(yǔ)音不好做,很多 to C 的產(chǎn)品都選擇只支持文字,但實(shí)時(shí)語(yǔ)音交互的用戶體驗(yàn)明顯是更好的。
雖然基于 VITS 很難實(shí)現(xiàn) ElevenLabs 級(jí)別質(zhì)量的語(yǔ)音,但基本可用是沒(méi)有問(wèn)題的。自己部署 VITS 的成本只要 $0.0005 / 1K 字符,是 OpenAI 和 Google Cloud TTS 價(jià)格的 1/30,ElevenLabs 價(jià)格的 1/360。這個(gè) $2 / 1M tokens 的語(yǔ)音合成成本也跟自己部署開源文本大模型的成本差不多,這樣文本和語(yǔ)音的成本就都降下來(lái)了。
因此如果真的打算把語(yǔ)音作為一個(gè)用戶體驗(yàn)的重大加分項(xiàng),基于開源自研語(yǔ)音模型不僅是必要的,也是可行的。
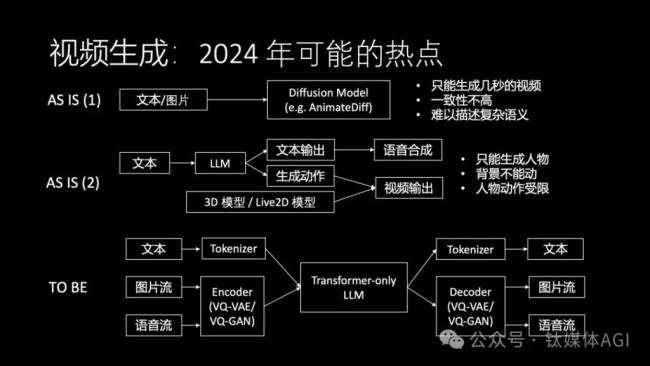
我們知道圖片生成現(xiàn)在已經(jīng)比較成熟,視頻生成會(huì)是2024年一個(gè)非常重要的方向。視頻生成不僅僅是生成素材這么簡(jiǎn)單,更重要的是讓每個(gè)人都能輕松成為視頻內(nèi)容的創(chuàng)作者,更進(jìn)一步,讓每個(gè) AI 數(shù)字分身都有自己的形象,可以用視頻的方式來(lái)交流。