
高數期末有救了?AI新方法解決高數問題,性能超越Matlab
選自arXiv
作者:Guillaume Lample、Francois Charton
機器之心編譯
參與:魔王
數學也可以是一種自然語言,而使用機器翻譯方法就可以解決數學問題,這是 Facebook 科學家提出的用神經網絡精確解符號計算的方法。
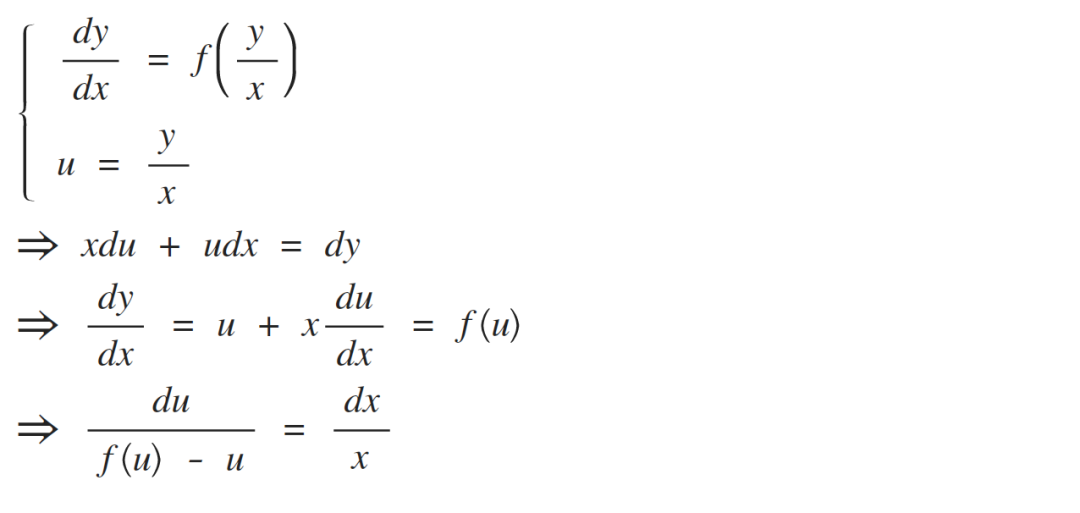
來,回顧一下常微分方程
機器學習的傳統是將基于規則的推斷和統計學習對立起來,很明顯,神經網絡站在統計學習那一邊。神經網絡在統計模式識別中效果顯著,目前在計算機視覺、語音識別、自然語言處理等領域中的大量問題上取得了當前最優性能。但是,神經網絡在符號計算方面取得的成果并不多:目前,如何結合符號推理和連續表征成為機器學習面臨的挑戰之一。
近日,來自 Facebook 的 Guillaume Lample 和 Franc?ois Charton 發表了一篇論文,他們將數學(具體來說是符號計算)作為 NLP 模型的目標。更準確地講,研究者使用序列到序列模型(seq2seq)解決符號數學的兩個問題:函數積分和常微分方程(ODE)。這兩個問題不管對接受過數學訓練的人還是計算機軟件而言都是難題。

論文鏈接:
Facebook 研究者首先提出一種可用于 seq2seq 模型的數學表達式和問題表示,并討論了問題空間的大小和結構。然后展示了如何為積分和一階、二階微分方程的監督式訓練生成數據集。最后,研究者對數據集應用 seq2seq 模型,發現其性能超過當前最優的計算機代數程序 Matlab 和 Mathematica。
數學也是一門自然語言
將數學表達式變成「樹」
數學表達式可被表示為樹的形式:運算符和函數是內部節點,運算域是子節點,常量和變量是葉節點。下面三棵樹分別表示 2 + 3 × (5 + 2)、3x^2 + cos(2x) ? 1 和
:

Facebook 研究者將這些數學表達式看作一組數學符號組成的序列。2 + 3 和 3 + 2 是不同的表達式,√4x 和 2x 也是如此,它們都可以通過不同的樹來表示。大部分數學表達式表示有意義的數學對象。x / 0、√?2 或 log(0) 也是正當的數學表達式,盡管它們未必具備數學意義。
很多數學問題都可被重新定義為對表達式或樹的運算。這篇論文探討了兩個問題:符號積分和微分方程。二者都可以將一個表達式變換為另一個,如將一個方程的樹映射到其解的樹。研究者將其看作機器翻譯的一種特例。
將樹作為序列
相比于 seq2seq 模型,「樹-樹」模型更加復雜,訓練和推斷速度也更慢。出于簡潔性考慮,研究者選擇使用 seq2seq 模型,此類模型可以高效生成樹,如在語境成分分析中,這類模型用于預測輸入句子對應的句法分析樹。
使用 seq2seq 模型生成樹需要將樹與序列對應起來。為此,研究者使用前綴表示法(又叫「波蘭表示法」),將每個節點寫在其子節點前面,順序自左至右。例如,數學表達式 2+ 3?(5+ 2) 按照前綴表示法可被表示為序列 [+ 2 ? 3 + 5 2]。與更常見的中綴表示法 2 + 3 ? (5 + 2) 相比,前綴序列沒有括號、長度更短。在序列內,運算符、函數或變量都由特定 token 來表示,符號位于整數前面。表達式與樹之間存在映射關系,同樣地,樹與前綴序列之間也存在一對一的映射。
生成隨機表達式
要想創建訓練數據,我們需要生成隨機數學表達式。但是,均勻采樣具備 n 個內部節點的表達式并不是一項簡單的任務。樸素算法(如使用固定概率作為葉節點、一元節點、二元節點的遞歸方法)傾向于深的樹而非寬的樹。以下示例展示了研究者想使用相同概率生成的不同樹。
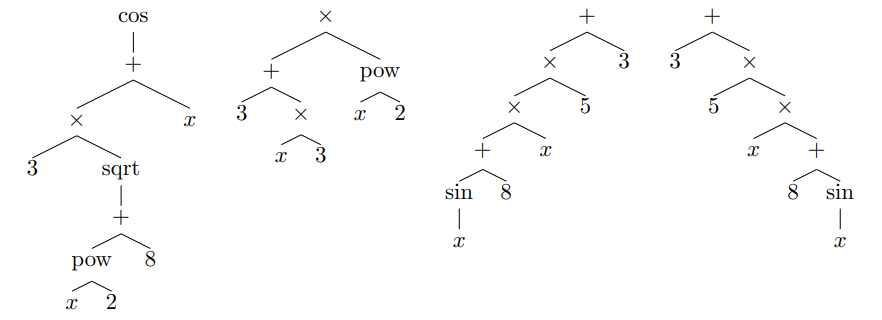
計數表達式(COUNTING EXPRESSION)
接下來需要研究所有可能表達式的數量。表達式是基于有限的變量(即文字)、常量、整數和一系列運算符創建得到的,這些運算符可以是簡單函數(如 cos 或 exp),也可以更加復雜(如微分或積分)。準確來講,研究者將問題空間定義為:
至多具備 n 個內部節點的樹;
p_1 個一元運算符(如 cos、sin、exp、log);
p_2 個二元運算符(如+、?、×、pow);
L 個葉節點,包含變量(如 x、y、z)、常量(如 e、π)、整數(如 {?10, . . . , 10})。
圖 1 展示了不同內部節點數量所對應的二元樹數量(C_n)和 unary-binary 樹數量(S_n)。研究者還展示了不同運算符和葉節點組合所對應的表達式數量(E_n)。

圖 1:不同數量的運算符和葉節點所對應的樹和表達式的數量。p_1 和 p_2 分別對應一元運算符和二元運算符的數量,L 對應葉節點數量。最下方的兩條曲線對應二元樹和 unary-binary 樹的數量。最上方兩條曲線表示表達式的數量。從該圖可以觀察到,添加葉節點和二元運算符能夠顯著擴大問題空間的規模。
萬事俱備,只欠數據集
為數學問題和技術定義語法并隨機生成表達式后,現在需要為模型構建數據集了。該論文剩余部分主要探討兩個符號數學問題:函數積分和解一階、二階常微分方程。
要想訓練網絡,首先需要包含問題及其對應解的數據集。在完美情況下,研究者想要生成能夠代表問題空間的樣本,即隨機生成待解的積分和微分方程。然而,隨機問題的解有時并不存在或者無法輕松推導出來。研究者提出了一些技術,生成包含積分和一階、二階常微分方程的大型訓練數據集。
積分
研究者提出三種方法來生成函數及其積分。
前向生成(Forward generation,FWD):該方法直接生成具備多達 n 個運算符的隨機函數,并通過計算機代數系統計算其積分。系統無法執行積分操作的函數即被舍棄。該方法生成對問題空間子集具備代表性的樣本,這些樣本可被外部符號數學框架成功求解。
后向生成(Backward generation,BWD):該方法生成隨機函數 f,并計算其導數 f',將 (f', f) 對添加到訓練集。與積分不同,微分通常是可行的且速度極快,即使是面對非常大的表達式。與前向生成方法相反,后向生成方法不依賴外部符號積分系統。
使用部分積分的后向生成(Backward generation with integration by parts (IBP)):該方法利用部分積分:給出兩個隨機生成函數 F 和 G,計算各自的導數 f 和 g。如果 fG 已經屬于訓練集,我們就可以知道其積分,然后計算 Fg 的積分:
該方法可在不依賴外部符號積分系統的情況下生成函數積分,如 x^10 sin(x)。
一階常微分方程(ODE 1)
如何生成具備解的一階常微分方程?研究者提出了一種方法。給定一個雙變量函數 F(x, y),使方程 F(x, y) = c(c 是常量)的解析解為 y。也就是說,存在雙變量函數 f 滿足
。對 x 執行微分,得到 ?x, c:
其中 f_c = x |→ f(x, c)。因此,對于任意常量 c,f_c 都是一階常微分方程的解:

利用該方法,研究者通過附錄中 C 部分介紹的方法生成任意函數 F(x, y),該函數的解析解為 y,并創建了包含微分方程及其解的數據集。
研究者沒有生成隨機函數 F,而是生成解 f(x, c),并確定它滿足的微分方程。如果 f(x, c) 的解析解是 c,則我們計算 F 使 F (x, f(x, c)) = c。通過上述方法,研究者證明,對于任意常量 c,x |→ f(x, c) 都是微分方程 3 的解。最后,對得到的微分方程執行因式分解,并移除方程中的所有正因子。
使用該方法的必要條件是生成解析解為 c 的函數 f(x, c)。由于這里使用的所有運算符和函數都是可逆的,因此確保 c 為解的簡單條件是確保 c 在 f(x, c) 樹表示的葉節點中僅出現一次。生成恰當 f(x, c) 的直接方式是使用附錄中 C 部分介紹的方法采樣隨機函數 f(x),并將其樹表示中的一個葉節點替換成 c。以下示例展示了全過程:
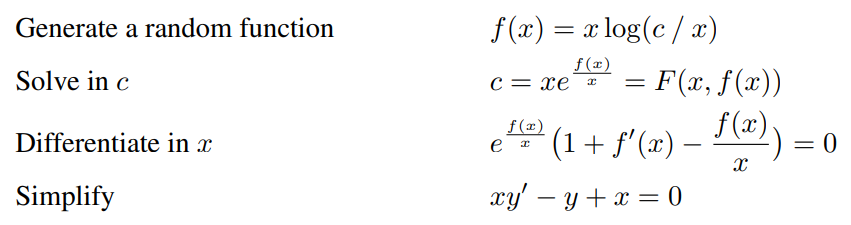
二階常微分方程(ODE 2)
前面介紹的生成一階常微分方程的方法也可用于二階常微分方程,只需要考慮解為 c_2 的三變量函數 f(x, c_1, c_2)。
和之前方法一樣,研究者推導出三變量函數 F,使 F (x, f(x, c_1, c_2), c_1) = c_2。對 x 執行微分獲得一階常微分方程:

其中 f_c1,c2 = x |→ f(x, c1, c2)。如果該方程的解為 c_1,則我們可以推斷出另一個三變量函數 G 滿足:
對 x 執行第二次微分,得到以下方程:
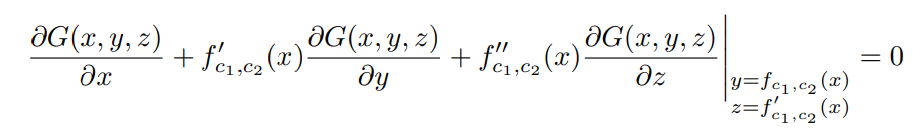
因此,對于任意常量 c_1 和 c_2,f_c1,c2 是二階常微分方程的解:
通過該方法,研究者創建了二階常微分方程及其解的對,前提是生成的 f(x, c_1, c_2) 的解為 c_2,對應一階常微分方程的解為 c_1。
對于 c_1,研究者使用了一個簡單的方法,即如果我們不想其解為 c_1,我們只需跳過當前方程即可。盡管簡單,但研究者發現在大約一半的場景中,微分方程的解是 c_1。示例如下:
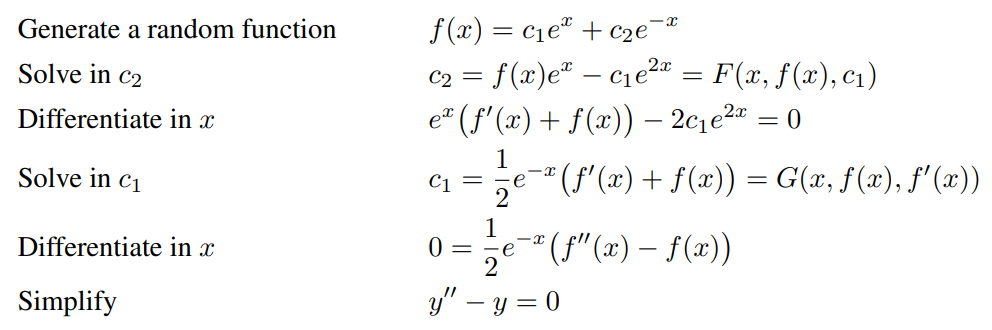
數據集清洗
方程簡化:在實踐中,研究者簡化生成的表達式,以減少訓練集中唯一方程的數量,從而縮短序列長度。此外,研究者不想在可以使模型預測 x+5 的情況下,令其預測 x + 1 + 1 + 1 + 1 + 1。
系數簡化:在一階常微分方程中,研究者更改一個變量,將生成的表達式變為另一個等價表達式。研究者對二階常微分方程也使用了類似的方法,不過二階方程有兩個常量 c_1 和 c_2,因此簡化略微復雜一些。
無效表達式:最后,研究者從數據集中刪除無效的表達式。如果子樹的值不是有限實數(如?∞、+∞或復數),則丟棄該表達式。
實驗
數據集
表 1 展示了數據集統計情況。如前所述,研究者觀察到后向生成方法生成的導數(即輸入)比前向生成器要長得多,詳見附錄中 E 部分內容。

表 1:不同數據集的訓練集大小和表達式長度。FWD 和 IBP 生成樣本的輸出比輸入長,而 BWD 方法生成樣本的輸出比輸入短。和 BWD 類似,ODE 生成器輸出的解也比方程短。
模型
對于所有實驗,研究者訓練 seq2seq 模型來預測給定問題的解,即預測給定函數的原函數或預測給定微分方程的解。研究者使用 transformer 模型 (Vaswani et al., 2017),該模型有 8 個注意力頭、6 個層,維度為 512。
研究者使用 Adam 優化器訓練模型,學習率為 10^?4。研究者移除長度超過 512 個 token 的表達式,以每批次 256 個方程來訓練模型。
在推斷過程中,表達式通過集束搜索來生成,并使用早停法。研究者將集束中所有假設的對數似然分數按其序列長度進行歸一化。這里使用的集束寬度為 1(即貪婪解碼)、10 和 50。
在解碼過程中,模型不可避免地會生成無效的前綴表達式。研究者發現模型生成結果幾乎總是無效的,于是決定不使用任何常量。當模型生成無效表達式時,研究者僅將其作為錯誤解并忽略它。
評估
在每個 epoch 結束時,研究者評估模型預測給定方程解的能力。但是,研究者可以通過對比生成表達式及其參考解,輕松核對模型的正確性。
因此,研究者考慮集束中的所有假設,而不只是最高分的假設。研究者核實每個假設的正確性,如果其中一個正確的話,則模型對輸入方程成功求解。因此,「Beam size 10」的結果表示,集束中 10 個假設里至少有一個是正確的。
結果
下表 2 展示了模型對函數積分和微分方程求解的準確率。

表 2:模型對函數積分和微分方程求解的準確率。所有結果均基于包含 5000 個方程的留出測試集。對于微分方程,使用集束搜索解碼顯著提高了模型準確率。
下表 3 展示了不同集束大小時模型的準確率,此處 Mathematica 有 30 秒的超時延遲。

表 3:該研究提出的模型與 Mathematica、Maple 和 Matlab 在包含 500 個方程的測試集上的性能對比情況。此處,Mathematica 處理每個方程時有 30 秒的超時延遲。對于給定方程,該研究提出的模型通常在不到一秒的時間內即可找出解。
下表 4 展示了該研究提出模型能解而 Mathematica 和 Matlab 不能解的函數示例:

表 4:該研究提出模型能解而 Mathematica 和 Matlab 不能解的函數示例。對于每個方程,該研究提出的模型使用貪婪解碼找出有效解。
下表 5 是模型對方程返回的 top 10 假設。研究者發現,所有生成結果實際上都是有效解,盡管它們的表達式迥然不同。
表 5:通過集束搜索方法,模型對一階常微分方程
返回的 top 10 生成結果。
下表 6 對比了使用不同訓練數據組合訓練得到的 4 個模型在 FWD、BWD 和 IBP 測試集上的準確率情況。

表 6:該研究提出的模型對函數積分求解的準確率。FWD 訓練的模型在對來自 BWD 數據集的函數執行積分時性能較差。
FWD 訓練模型有時可對 SymPy 無法求積分的函數執行積分操作,下表 7 展示了此類函數的示例:

表 7:FWD 訓練模型可求積分而 SymPy 不可求積分的函數/積分示例。盡管 FWD 模型僅在 SymPy 可求積分函數的子集上訓練,但它可以泛化至 SymPy 不可求積分的函數。
下表 8 展示了超時值對 Mathematica 準確率的影響。增加超時延遲的值可提高準確率。

表 8:在不同超時值情況下,Mathematica 對 500 個函數求積分的準確率。隨著超時延遲值增大,超時次數下降,因而失敗率下降。在 3 分鐘極限情況下,超時次數僅帶來 10% 的失敗。因此,沒有超時的準確率不會超過 86.2%。
:22大領域、127個任務,機器學習 SOTA 研究一網打盡。